南开新闻网记者 闫瑾 通讯员 林珈亦 冉启斌
近来,南开大学语言实验与计算交叉科学实验室在推动传统语言文化智能化转化方面,取得了一系列新的研究突破。该实验室入选天津市高校社会科学实验室,实验室研究团队又于今年获批为天津市高校哲学社会科学创新团队。这些成绩不仅巩固了实验室在国内学术界的地位,也标志着其在跨学科研究和文化传承方面取得了显著进展。
南开大学语言实验与计算交叉科学实验室肇始于1986年建立的语音实验室,历经近40年的积淀和发展,已逐渐成为国内领先的语言学科研平台之一。实验室一直以语音学研究为核心,辅以技术手段深入发掘和分析汉语乃至世界语言的发音规律、变化特点,取得了大量科研成果。实验室研究人员历年来出版专著40余部,发表学术论文600余篇,承担国家社科基金重大项目2项,包括国际合作项目在内的其他项目20余项,获得教育部人文社科优秀成果二等奖等奖项,获得专利数项。实验室曾自主开发语音分析软件“桌上语音工作室(MiniSpeechLab)”,曾获国家教学软件大赛一等奖、国家高等教育教学成果二等奖等奖项。实验室研究人员现在主办有学术网站3个,微信公众号2个。
近年来,随着信息技术的快速发展,尤其是人工智能领域的突破性进展,实验室积极响应党和国家号召,主动朝“语言实验与计算”转向,积极对接国家和社会需求,将研究领域从传统语言学扩展至以语言学为中心的交叉学科,探索语言与前沿科学的结合。
立足语言学的跨学科视角研究转型
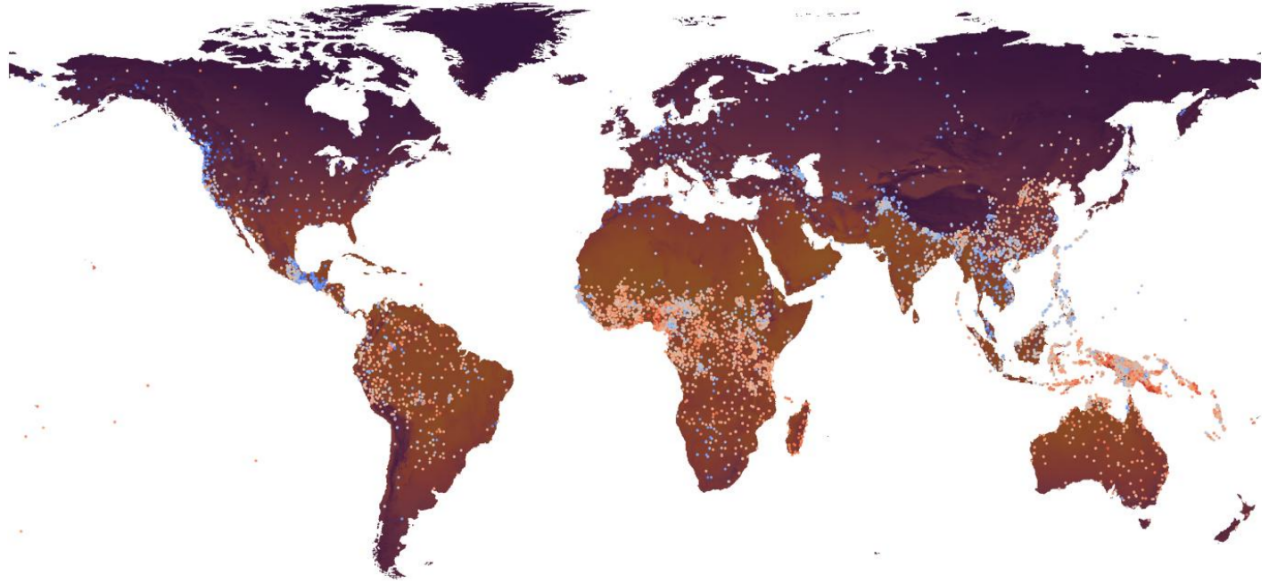
实验室自成立以来,一直致力于语音学的本体研究,积累了丰富的经验和资源。随着社会需求的变化和科技的快速发展,传统的语言学研究模式已难以完全满足当今社会对语言研究的需求。近年来,实验室积极响应国家“培育交叉融合的新兴专业”号召,尝试将数据库技术、自然环境、数理统计分析、分子生物学方法、计算机技术等跨学科手段引入语言学研究中,在新的研究领域中进行探索。研究团队先后建立有10余个中大型数据库,部分数据库纳入欧洲马普研究院(Max Planck Institute)跨语言关联数据库群和国家语委语言数据库集群。研究团队采用大数据思路,系统性地大规模录制汉语中名动同形的特殊形式,探讨汉语名词和动词究竟是否具有语音上的差异,成果发表于语音学国际顶尖期刊。团队采集世界100种语言中的正反义词的语音形式,分析正反义词的音义分化问题,成果发表于一级顶尖期刊。团队收集60个基本核心词在世界范围61种语言中的词义衍生引申情况,从而考察不同语言使用民族对基本核心概念认知路径的共性与个性,成果发表于Nature旗下期刊。依托国家社科基金重大项目,研究团队开展了大量语言距离计算研究,制作了数百幅信息丰富的中国语言知识图谱。团队通过语言距离及相似度计算讨论语言的共性和差异,用系统发生学邻接树、邻网法等方法探讨汉语方言、民族语乃至世界语言的聚类分类、系统演化和接触模式等,发表了一系列成果。自然环境尤其是气候对人类的影响是学术界近年来特别关注的问题,团队在语言与自然环境关系的研究上紧盯国际前沿,利用中国境内丰富的语言资源进行空气湿度影响声调数量的生理介导作用研究,相关成果发表于Nature唯一的人文子刊上。团队还积极开展国际合作研究,与德国基尔大学卓越计划研究人员进行合作,利用国际大型数据库对语言响度与气温的关系重新进行深度分析,成果发表于美国科学院院刊姊妹刊PNAS Nexus,论文发表后引起了大量关注。
团队成果Temperature shapes language sonority: Revalidation from a large dataset(利用大型数据对气温影响语言响度的再证实)于2023年12月发表于PNAS Nexus。该研究从当今社会人们普遍关注的气候问题入手,利用世界范围9,179个语档(doculects)、5,293种语言的大型数据研究了气温对语言响度的影响。研究发表受到境外媒体大量关注,美国科学促进会科学研究新闻平台优睿科(EurekAlert!)、科学新闻网(www.sci.news)、美国物理学家组织网、德国科学信息服务网、德国科学信息网、俄罗斯Naked Science等进行了报道。
语言智能技术助力传统语言文化的传承与发扬
实验室结合国家“人工智能发展规划”的政策导向,逐步从单一的语言学本体研究转向本体和应用研究并重,既重视前沿学科理论的探索,又注重技术的实际应用。研究团队从语言学角度开展了语音识别、语音合成、语种识别、声纹识别、语音评分、国际音标自动转写等智能技术的研究与开发,借助于深度学习和人工智能技术,实验室开发出了一系列语音技术工具,推动了语言智能化应用的快速发展。例如利用深度学习模型,成功实现了国际音标的实时自动转写等,这不仅可以为语言田野调查的大量转写工作带来巨大方便,也将为人机交互带来新的思路。在技术研发的过程中,研究团队建立了多方言、多语种的大型语料库,文本语料库达到近2T,语音语料库估计达到三四万个小时以上,积累了非常丰富的语音资源,不仅为语言研究提供了宝贵的资源支持,同时也为语音识别、语音合成等技术的开发奠定了坚实的基础。
在国家大力倡导文化自信、推动中华优秀传统文化创造性转化和创新性发展的背景下,实验室依托南开大学深厚的文化底蕴,积极探索如何将现代智能技术与传统文化相结合,围绕中华优秀传统语言和文化开展语言大模型研究、语言信息化处理研究以及数智复原工程研究。
实验室通过语言大模型研究和语言信息化处理项目,深入研究中华优秀传统文化的智能化保存与传播,特别是在诗词文化的数字化保护和传承方面进行了一系列探索。中国古诗词的吟诵在中华优秀传统文化中具有独特地位,然而现在会吟诵的人越来越少。如何保存并传承古诗词吟诵这一文化遗产是一个问题。研究团队运用语音克隆和语音合成技术,开展了多家传统诗词吟诵的智能保存与生成研究。这从技术角度为优秀传统文化创造性传承和创新性发展提供了答案。
目前全世界约有7000多种语言,但是约有96%的语言只有3%的人使用。据预计到21世纪将只有几百种语言仍然还在使用。随着语言的濒危和消亡,这些语言所承载的文化也将永远消失在人类历史的长河中。语言濒危已经受到联合国教科文组织的高度重视,发布了语言活力指数评估,不同的国际组织和国家也开展了各种形式的濒危语言纪录项目。中国境内语言的濒危形势也非常严重,会使用民族语言和汉语方言的人群越来越少。
有鉴于此,研究团队依托人工智能(AI)技术,率先提出“濒危语言文化智能保存”的理念和方法,并从技术角度进行了开拓性的探索。“语言智能保存”可以使一种语言具有实时生成能力和交互能力,从而真正达到语言保护传承的目的。研究团队以满语为试点进行了自动翻译、满语语音合成与识别等研究,在“语言智能保存”研究上取得了初步成效。“语言智能保存”的最终实现,将可以实现濒危语言的动态保存和永久保存。借助于人工智能技术,“语言智能保存”将有助于优秀语言文化的传承发展,也将为人类语言多样性的保护贡献技术方案。
满语在100多年以前是占有明显优势的语言,如今满语却只在黑龙江几个村庄的老人中使用,成为了极端濒危的语言。满语中承载的大量文化内容也濒临不存。研究团队以满语为试点进行语言智能保存研究。团队构建了较大规模的满语文数据库,建立了初步的满-汉自动互译系统(Machine Translation),并正在进行满语语音识别(ASR)和语音合成(TTS)的研究。利用人工智能技术进行濒危语言保存之后的满语文,将像大模型(LLM)一样具备自动生成满语语句、语篇的能力,并具有与人实时对话的互动功能。如果能够突破语言智能保存的瓶颈,将摆脱语言濒危的困境,濒危语言将通过语言智能技术实现永久保存。
将科研教学面向公众服务
在保持语言学基础研究的深度与广度的同时,团队始终致力于将研究成果转化为能够服务于公众和社会的实际应用。研究团队主持的微信公众号“语言实验与计算”,在建立以来的两年多时间里发布原创推文210篇,关注用户数7000余名。研究团队还搭建了“语言实验与计算共享资源网(www.ranqibin.com)”和“口音汉语在线(www.globalaccentchinese.com)”两个网站,不仅为学术研究提供了丰富的资源,还为广大语言学习者和爱好者提供了便利的学习工具。其中“口音汉语在线”已运行8年多,目前总访问量超过35万人次(截止2024年10月21日为353233次),中国知网中引用30余次。网站数据库于2021年在O-COCOSDA(东方语言数据库标准化国际会议,新加坡)上进行展示。网站数据库还受邀加入“国家语言资源服务平台(http://fw.ywky.edu.cn/#/details/2077)”。该在线数据库网站收录开放偏误条目600余条,开放音频文件10000余个,曾经得到“中国社会科学网”、“今日头条”、《人民日报》(海外版)等重要媒体的报道。依托该网站研究团队也成功申请到新型实用专利1项(专利号:ZL 2016 3 056662.5)。
研究团队还十分重视科研成果的社会普及工作。在第二十二届推广普通话宣传周时,团队自己制作系列专业推普视频在微信视频号上予以发布,取得了良好反响。研究团队通过长时间收集中国语言核心词音标转写数据,利用语言距离计算技术制作“中国语言家族星系视频”、“中国语言家族动态视频”等,生动诠释了中国语言家族的内部和外部关系,从语言的角度增强公众的中华民族共同体意识。团队制作的“中国语言关系动态网络图谱”,以在线交互方式全方位、多角度呈现中国汉语方言、少数民族语言之间的动态网络关系。研究团队还探索设计了“言·色”“语·宙”等系列文创制品,向公众普及中国语言和语言学知识。
“中国语言家族星系视频”按照采集到的中国境内语言1108个地点的核心词音标形式,按照ASJP模式距离计算方法量度中国语言中的9个语族和其他语言与整个中国语言大家庭之间的关系。视频依据的数据采集量庞大,计算量达到数十亿,聚类制图方法先进。每个语族的聚类图详细展现了该语族的内部聚类状态。视频曾多次在会议、论坛、讲座中播放,获得良好反响。
展望未来,南开大学文学院“语言实验与计算”团队表示,将秉持“坚守中华文化立场,坚持创造性转化、创新性发展,赓续中华文脉”的宗旨,继续深入探索语言与科技的文理结合之路,推动传统语言文化的智能化转型与传播。团队计划在数智传承与智能转化方面开展更多深入研究,尤其是在中华优秀传统文化、濒危语言的智能保存、边境语言的信息化处理等领域。通过加强与国内外科研机构、企业和文化单位的合作,研究团队将不断推进智能语言技术的创新与应用。
|